Universidade Federal de Rondônia, Porto Velho - RO
v. 1, n. 10, dez. 2023
O desenvolvimento do ScraperCI: uma aplicação online para extração de dados na Web, por Helton Luiz dos Santos Graciano e Rogério Aparecido Sá Ramalho
O desenvolvimento do ScraperCI: uma aplicação online para extração de dados na Web
Helton Luiz dos Santos Graciano e Rogério Aparecido Sá Ramalho helton.graciano@gmail.com | ramalho@ufscar.br
O desenvolvimento tecnológico e a explosão de recursos informacionais na Web têm impulsionado uma transformação sem precedentes, tornando a Internet o maior repositório de informações da atualidade. A crescente quantidade de dados gerados por pessoas, aplicativos e dispositivos é armazenada de maneiras diversas, resultando em ineficiência e dificuldade de acesso às informações nas rotinas das organizações, afetando sua vantagem competitiva e tomada de decisões.
A falta de diretrizes e procedimentos adequados para lidar com essa diversidade de dados e formas de armazenamento resulta em morosidade e perda de informações. É essencial gerenciar e disponibilizar os dados no momento, formato e local necessários, além de explorá-los por meio de ferramentas de recuperação eficientes. Nesse contexto, a utilização de Web scrapers como ferramenta de coleta de dados em ambientes digitais desponta como uma possibilidade promissora para a Ciência da Informação e seus profissionais, permitindo resgatar informações em massa de maneira ágil.
Foi analisado o potencial dessas ferramentas de recuperação e como os profissionais podem aproveitar suas habilidades para análises mais precisas dos dados recuperados, através da criação de um scraper utilizando a linguagem Python, abordando seus fundamentos, conceitos, desafios e principalmente as contribuições que a ferramenta pode trazer para o aprimoramento das habilidades dos profissionais da informação.
O protótipo, denominado ScraperCI, foi desenvolvido com fins didáticos e disponibilizado online através do endereço http://scraperci.info permitindo buscas relacionadas e conectadas à base de dados BRAPCI como ambiente experimental. A proposta da ferramenta foi analisar de maneira prática as contribuições de um scraper na coleta de dados e sua aplicação pelos profissionais da informação, diante das crescentes demandas informacionais.
Apesar das funcionalidades oferecidas pelos repositórios informacionais, incluindo o BRAPCI, nem sempre são de fácil compreensão e muitas vezes estão limitadas ao acervo do próprio repositório. Nesse sentido, ferramentas como o ScraperCI apresentam uma vantagem significativa, pois podem ser configuradas para extrair dados de diversos portais, além de permitir a personalização da recuperação de campos específicos de acordo com a relevância para o usuário, bem como o cruzamento de informações.
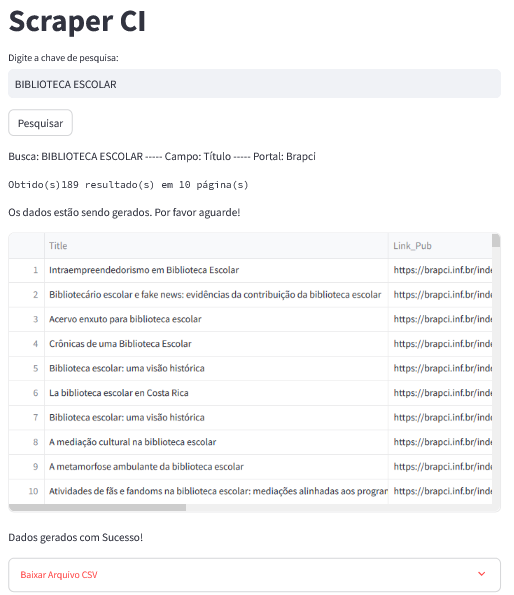
Na imagem, parte da interface do ScraperCI
A ferramenta permite o download dos dados tabulados no formato CSV (Comma Separated Values), possibilitando diversas análises por meio da importação do arquivo para ferramentas como Microsoft Excel, Google Sheets, Libre Office Calc ou R Studio. Com as informações estruturadas, elas podem ser submetidas a análises resultando em conclusões diversas.
Na imagem, parte da interface do ScraperCI, com os resultados de uma consulta.
Foi promovido uma discussão sobre o uso de Web scrapers para coleta de dados, abordando suas características conceituais e práticas. Apesar dos desafios relacionados ao grande volume de conteúdo disponível na Web e à eficiência no processo de recuperação, o uso de Web scrapers pode contribuir para a coleta rápida, sistemática e padronizada de diversos tipos de conteúdo na internet. Nesse sentido, foi observado um cenário desafiador para a Ciência da Informação no contexto contemporâneo, devido à globalização do conhecimento e ao compartilhamento massivo de grandes quantidades de informações. A demanda por informações de qualidade, que gerem valor e tenham potencial inovador, é cada vez maior tanto para tomadas de decisão individuais quanto corporativas.
Foi demonstrado que a combinação de conhecimentos teóricos sobre recuperação da informação e habilidades em linguagens de programação, como o Python, pode resultar na construção de ferramentas que auxiliam os usuários na busca por informações em ambientes digitais e no desempenho das atividades dos profissionais da informação.
O estudo de caso realizado utilizando o ScraperCI demonstrou que essa tecnologia é exitosa na coleta de dados, proporcionando maior produtividade e ampliando as possibilidades de extração de recursos informacionais na Web. Isso sugere que tal ferramenta é uma opção viável a ser explorada pelos profissionais da informação que estão no centro do processo de transformação digital atual.
Apesar das limitações do protótipo, a utilização de Web scrapers favorece a automatização dos processos de coleta de dados, trazendo benefícios como obtenção rápida e eficiente de grandes volumes de informações, flexibilidade na escolha dos dados a serem coletados, customização dos métodos de busca, redução de erros em comparação à coleta manual, potencialização da análise de dados e redução de custos.
Em pesquisas futuras, existe a perspectiva de ampliar o escopo da ferramenta desenvolvida, incorporando funcionalidades que permitam a recuperação de informações em diversos repositórios, além de aprimorar os métodos de busca para melhorar tanto o tempo de resposta quanto a qualidade dos resultados para o usuário.
Além disso, é possível explorar as tendências atuais na recuperação de recursos informacionais em ambientes digitais, bem como a necessidade crescente da Ciência da Informação de se adaptar a essa realidade indo além das análises técnicas e produtivas e considerando os impactos sociais do uso dessa tecnologia.
É importante que os profissionais da Ciência da Informação estejam familiarizados com os sistemas de recuperação de informações e atualizem suas habilidades e ferramentas para coletar informações de forma precisa e eficiente. Isso estimulará a busca por possibilidades inovadoras na atuação desses profissionais, utilizando ferramentas que tornem a recuperação e análise de informações mais eficientes e alinhadas às demandas atuais e futuras da profissão.
Espera-se que essa temática desperte o interesse por novas pesquisas sobre o uso de Web scrapers para coleta de dados, estimulando outros pesquisadores interessados nesse assunto e contribuindo para uma maior disseminação de estudos na área da Ciência da Informação relacionados ao uso de Web scrapers.
Por fim, destaca-se que, diante das crescentes demandas informacionais, são necessárias mais pesquisas para aprofundar e compreender melhor essa temática, podendo favorecer o desenvolvimento de atividades que respondam de forma mais eficiente às demandas atuais em relação à recuperação de dados em grandes volumes.
GRACIANO, Helton Luiz dos Santos. ScraperCI: um protótipo de Web scraper para coleta de dados. 2022. Dissertação (Mestrado em Ciência da Informação) – Universidade Federal de São Carlos, São Carlos, 2022. Disponível em: https://repositorio.ufscar.br/handle/ufscar/17166 . Acesso em 07 dez. 2023.
Mestre em Ciência da Informação e Especialista em Gestão da Produção pela Universidade Federal de São Carlos. Bacharel em Engenharia de Controle e Automação pela Universidade Paulista. Atualmente é Engenheiro de Manutenção de Aeronaves – LATAM.
É Professor do Departamento de Ciência da Informação, da MBA Informação, Tecnologia e Inovação para Negócios e do Programa de Pós-Graduação em Ciência da Informação da Universidade Federal de São Carlos. Atua também junto ao Programa de Pós-Graduação da Universidade Estadual de Londrina. Líder do Núcleo de Informação, Tecnologia e Inovação (ITI UFSCar). É bolsista de Produtividade em Pesquisa do Conselho Nacional de Desenvolvimento Científico e Tecnológico.
Doutor e Mestre em Ciência da Informação pela Universidade Estadual Paulista. Pós Doutor em Ciência da Informação pela Universidade Estadual de Londrina. Bacharel em Ciência da Computação pela Faculdades Adamantinenses Integradas.
Redação: Helton Luiz dos Santos Graciano e Rogério Aparecido Sá Ramalho
Quaisquer opiniões, constatações, sugestões ou recomendações expressas neste material são de responsabilidade dos autores e não refletem necessariamente as opiniões da Revista, seus Editores e Apoiadores.